
Spec-aligned training data for text, image, video, and audio. We combine clear labeling guidelines, dual-stage human QA, and lightweight automation to keep outputs consistent across batches and teams. Deliverables include audit trails, sampled QA results, and issue logs—so your datasets meet spec and remain reliable over time.
Guideline Design & Taxonomy Setup
Custom ontologies and annotation guides aligned with your objectives, so tasks are unambiguous and inter-annotator agreement is high from day one.
Annotation & Review Workflow
Two-stage workflow (Annotator + Reviewer) with versioned datasets, audit trails, and ongoing calibration to keep quality consistent as volumes and teams grow.
Automated Consistency Checks
Conflict detection, overlap checks, and quality heuristics to flag drift early, cutting manual rework and keeping throughput predictable.
Final QA & Dataset Delivery
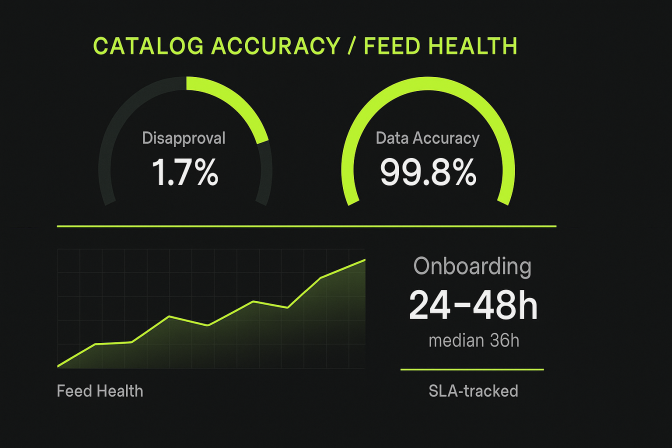
Consolidated datasets validated for schema accuracy, file integrity, and statistical balance, delivered as CSV, JSON, or TFRecord (as needed) and ready for direct model training.
Service Outcomes
- Agreed ontology, label schema, and QA rubric before scaling.
- Dual-stage QA with documented disagreements, corrections, and fix-by deadlines.
- Inter-annotator agreement and error classes tracked and reviewed on a defined cadence.
- Clean, documented CSV/JSON/TFRecord outputs that integrate into training pipelines without extra triage

What types of data can Datqo annotate?
We annotate text, image, video, and audio data—including classification, sentiment, entity tagging, bounding boxes, polygon segmentation, OCR extraction/correction, and transcription. Workflows are modular, so you can combine task types in one project while keeping a single set of guidelines and QA metrics.
How does Datqo ensure labeling quality?
Every project starts with a pilot to lock the guidelines, edge cases, and acceptance criteria. Production runs through a two-stage QA flow (peer review + statistical sampling), with inter-annotator agreement and error rates tracked per batch. Deviations trigger guideline updates and calibration, and you receive QA metrics plus issue logs so quality doesn’t drift over time.
Can you integrate with my existing tools or storage?
Yes. We integrate with annotation tools like Label Studio, CVAT, and Doccano, or your own stack via APIs, S3/GCS buckets, or secure SFTP. All transfers are versioned and logged so every delivery is traceable and reproducible.
How do I start a pilot project?
Most pilots start with a time-boxed sample (typically 3,000–5,000 items) to validate guidelines, QA targets, and throughput. We align on scope and success metrics, run the pilot with dual-stage QA and reporting, then deliver a decision pack (results, issues, and recommended next steps) to scale, adjust scope, or pause.
Spec-aligned training data for text, image, video, and audio. We combine clear labeling guidelines, dual-stage human QA, and lightweight automation to keep outputs consistent across batches and teams. Deliverables include audit trails, sampled QA results, and issue logs—so your datasets meet spec and remain reliable over time.
Guideline Design & Taxonomy Setup
Custom ontologies and annotation guides aligned with your objectives, so tasks are unambiguous and inter-annotator agreement is high from day one.
Annotation & Review Workflow
Two-stage workflow (Annotator + Reviewer) with versioned datasets, audit trails, and ongoing calibration to keep quality consistent as volumes and teams grow.
Automated Consistency Checks
Conflict detection, overlap checks, and quality heuristics to flag drift early, cutting manual rework and keeping throughput predictable.
Final QA & Dataset Delivery
Consolidated datasets validated for schema accuracy, file integrity, and statistical balance, delivered as CSV, JSON, or TFRecord (as needed) and ready for direct model training.
Service Outcomes
- Agreed ontology, label schema, and QA rubric before scaling.
- Dual-stage QA with documented disagreements, corrections, and fix-by deadlines.
- Inter-annotator agreement and error classes tracked and reviewed on a defined cadence
- Clean, documented CSV/JSON/TFRecord outputs that integrate into training pipelines without extra triage
What types of data can Datqo annotate?
We annotate text, image, video, and audio data—including classification, sentiment, entity tagging, bounding boxes, polygon segmentation, OCR extraction/correction, and transcription. Workflows are modular, so you can combine task types in one project while keeping a single set of guidelines and QA metrics.
How does Datqo ensure labeling quality?
Every project starts with a pilot to lock the guidelines, edge cases, and acceptance criteria. Production runs through a two-stage QA flow (peer review + statistical sampling), with inter-annotator agreement and error rates tracked per batch. Deviations trigger guideline updates and calibration, and you receive QA metrics plus issue logs so quality doesn’t drift over time.
Can you integrate with my existing tools or storage?
Yes. We integrate with annotation tools like Label Studio, CVAT, and Doccano, or your own stack via APIs, S3/GCS buckets, or secure SFTP. All transfers are versioned and logged so every delivery is traceable and reproducible.
How do I start a pilot project?
Most pilots start with a time-boxed sample (typically 3,000–5,000 items) to validate guidelines, QA targets, and throughput. We align on scope and success metrics, run the pilot with dual-stage QA and reporting, then deliver a decision pack (results, issues, and recommended next steps) to scale, adjust scope, or pause.